


*****
Every Salesforce admin and architect I talk to uses Claude.
So do I. So does my grandma.
So does my dog, I suspect.
We can stop pretending that it’s controversial.
The more useful question, I’d wager, is which kind of question you're asking it — because "I use Claude for Salesforce" covers at least four entirely different jobs, and the gap between them is where teams get into deep trouble.
Here's a helpful framework I keep coming back to:
The answer is in what you already pasted in. No additional metadata required.
You drop an Apex class into Claude and ask what it does. You paste flow XML and ask if there are any obvious bugs. You ask for the syntax of a wrapper class, or a Lightning component skeleton.
This is the layer where Claude — with no connection to your org at all — does fine. It has read enough Salesforce documentation to know syntax, patterns, and common gotchas. As long as the context for the answer is right there in the prompt, you're good.
Most teams use Claude at L1 all day without thinking about it. Nothing wrong with that.
The question depends on the org, and Claude has to go fetch metadata to answer.
"What's the validation rule on Opportunity Stage?" "How is this flow triggered?" "Show me every field on Account with a default value." These need real metadata from your real org.
This is where MCP servers live. Salesforce's hosted MCP, the DX MCP for developers, community-built servers, custom internal wrappers — all sitting at L2. The pattern is the same: Claude guesses which API to call, calls it, reads the response, guesses what to call next, and eventually answers.
When the question is narrow, this works. When the developer already knows the file they're asking about, this works. When you're poking around an area of the org you understand, this works.
But L2 has an honest limit that doesn't get advertised: the model only sees what the tools return, and the tools return whatever happens to be wired up. Most teams I talk to don't fully know what their MCP setup actually covers. They installed it, it answers some questions, and they assume it answers all of them. It doesn't.
This is where "confidently wrong" lives.
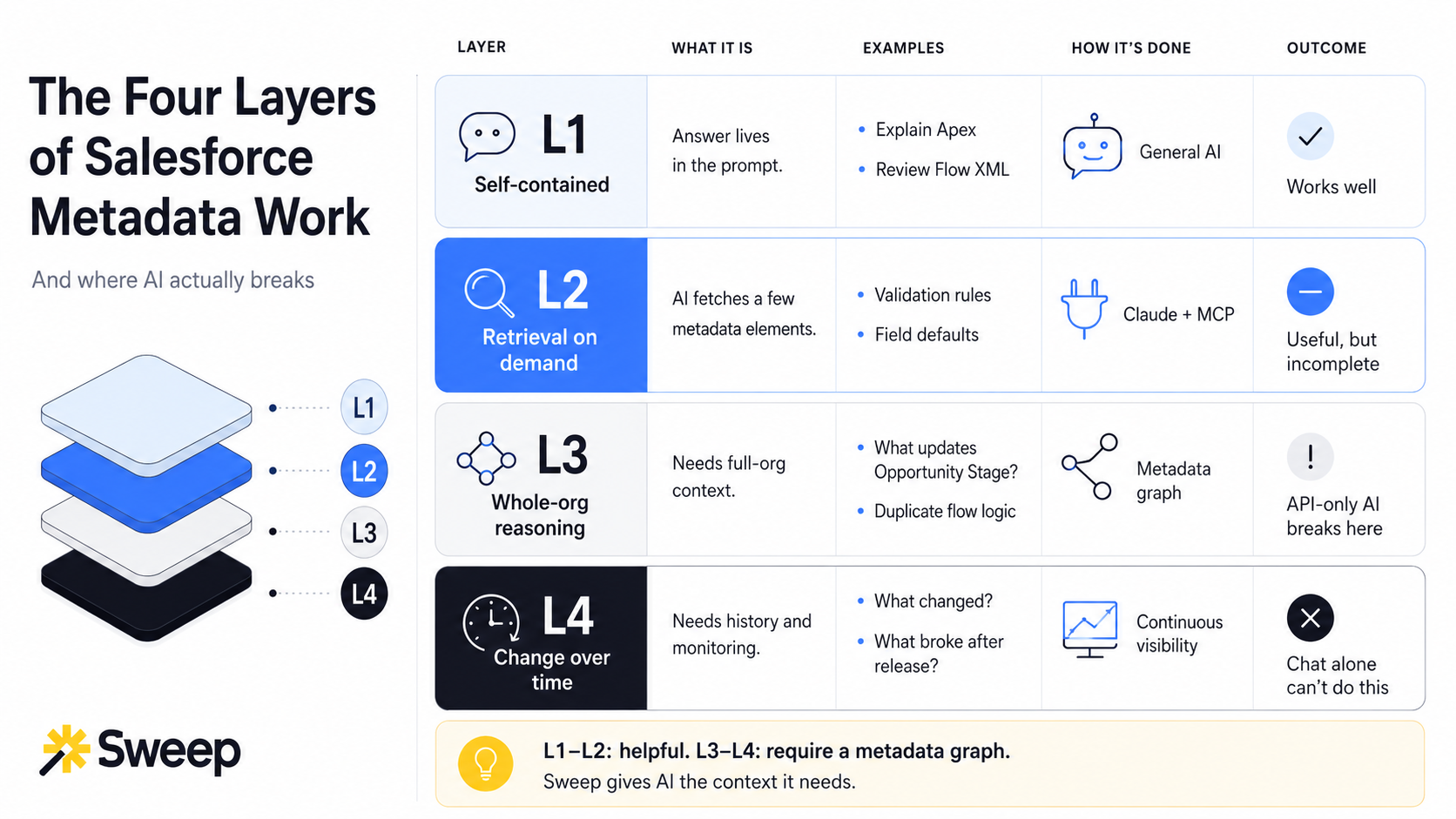
The question can't be answered by retrieving a few files. It needs the entire org as context.
"What updates Opportunity Stage automatically?" Sounds simple. The real answer might involve a workflow field update, an approval process, three flows, an Apex trigger, and a managed package. There is no Salesforce API for "what references this standard field." There is no Metadata API call that returns "all unused Apex classes" or "every label with zero references" or "all the duplicate logic across our flows."
The answer doesn't exist as a fetchable thing. It has to be built — by parsing every component, mapping every dependency, and walking the graph.
This is where retrieve-on-demand architectures break, and not by a little. A real enterprise Salesforce org is hundreds of megabytes to gigabytes of metadata. An LLM's context window holds, on a good day, around a megabyte of text. The math doesn't work. You cannot "just download everything." Any question that touches more than a handful of components starts to break the retrieve-on-demand approach, and in a real org, almost every question worth asking touches dozens.
A practical example from a recent customer call: they asked their internal Claude + CLI MCP setup, "find me the flows that use these record types." It returned ten flows. Six were wrong — pattern-matched on flow names without checking the actual XML. Sweep returned four. The four that actually use those record types.
That's L3. The honest answer her is "you need a different architecture."
The question is about change. What's different now versus last week. What just broke and why. Who modified this validation rule three months ago. Which configuration drifted between sandbox and prod since the last release.
This isn't a retrieval problem at all. It's a memory problem. No chat-based MCP tool can answer L4 questions in principle, because the architecture is question-at-a-time. The tool has no continuous view of the org. It can run a SOQL against SetupAuditTrail and hand you back raw rows — but raw rows aren't contextualized history. They're a spreadsheet of timestamps.
L4 needs a system that watches the org continuously, indexes what it sees, and connects every change back to the components it affects. That's a different kind of product than "AI with API access."
If you ask people where AI for Salesforce starts to fail, most will tell you about accuracy on a specific answer. "Claude got this flow wrong." "MCP missed a field."
That's not the breakpoint. The breakpoint is scope.
For a single question — one flow, one field, one validation rule — inaccuracy is annoying but tolerable. The developer who asked it usually knows enough to spot a wrong answer. AI at L1 and L2 is genuinely useful work even when it's a little wrong.
For a transformation project, inaccuracy is structurally different. CPQ to Agentforece Revenue Management migration. Workflow Rules to Flows. SKU rationalization. Permissions architecture rework. These are multi-step, multi-stakeholder projects with hundreds of decisions stacked on top of each other. Drift on a single fact at the start compounds across every downstream choice. By the time it ships, the architecture is built on something that wasn't true.
That's where teams realize their L2 tooling has been doing L3 work without telling them.
The four layers map cleanly to how Sweep thinks about the work — discover, design, build.
Discover lives at L3 and L4. The Unified Metadata Graph, indexed search across every component, dependencies including standard fields and picklist values and profile assignments, monitoring agents that surface what changed and what's broken.
Design lives at L3. Impact analysis grounded in the graph — what references this, what breaks if I touch it, where the duplicate logic already lives — so architecture decisions get made against what actually exists in the org instead of what the team thinks exists.
Build deploys against the same graph. Flows, fields, page layouts, permissions with full knowledge of dependencies, before anything ships.
No AI can scan a whole Salesforce org in one prompt. The retrieve-on-demand approach is a structural mismatch for L3 and L4 work, regardless of how many MCP tools the platform exposes. Sweep generates the metadata graph that AI can actually work with — Claude included. We ship our own MCP server for exactly this reason: any AI assistant you already use can plug into Sweep and inherit the graph instead of guessing at it.
If you want to know which layer your current setup actually serves, ask it this in your own org:
What updates Opportunity Stage automatically?
If you get a short, confident list back, ask a follow-up: Are you sure you found all of them — including workflow field updates, approval processes, every flow that touches the field, and managed package automation?
The honest answers are different from the confident ones. The gap between them is the gap between L2 and L3. That gap is where transformation projects live, and where AI alone has never been enough.
